|


|
此文章由 dootbear 原创或转贴,不代表本站立场和观点,版权归 oursteps.com.au 和作者 dootbear 所有!转贴必须注明作者、出处和本声明,并保持内容完整
Part 1
----------
彭博社超长新闻报道:“技术狂人”梁文锋正威胁美国在人工智能竞赛中的主导地位
梁文锋个子瘦削,性格内向,在会议上常常显得有些害羞,甚至紧张。
这位DeepSeek的创始人,这个近期颠覆全球人工智能领域的中国初创企业,说话常常磕磕绊绊,沉默时间也很长。
但新员工很快就会明白,别把他的沉思误认为胆怯。一旦他消化完讨论的细节,就会抛出一些尖锐、令人难以应对的问题,比如模型架构、计算成本,以及DeepSeek人工智能系统的各种技术细节。
员工们称他为“老板”(lǎo bǎn),在中国,这是对上司常见的尊称。
但不寻常的是,这位老板给年轻研究员甚至实习生的权限非常大,经常亲自走到他们桌前了解进展,还鼓励他们尝试一些不走寻常路的工程方案。只要能带来实际性能的提升,谈话越技术性越好。
梁文锋还会在公司内部的Lark工作群中亲自分享那些里程碑式的成果。
一位DeepSeek前员工表示:“他是个纯粹的技术宅。有时候我觉得他比研究员更懂研究。”
该员工和本文中许多受访者一样,因未获授权而要求匿名。
梁文锋和他创办的这家年轻公司在今年一月一炮而红,当时他们发布了名为R1的人工智能模型,给人一种“突破性进展”的震撼感。R1在多项标准化AI性能测试中击败了西方主导厂商,而DeepSeek声称,他们的基础模型开发成本只相当于GPT-4估算成本的5%。
这些测试结果引发了美国市场高达1万亿美元的抛售潮,也让人质疑美国试图通过出口管制来减缓中国AI进展的战略。亚马逊和微软争相将DeepSeek的模型纳入各自的云服务,跟Meta和Mistral AI的竞争产品并列。亚马逊语言模型平台负责人迪奥(Atul Deo)表示:“基本上就是一个周末的时间,关于DeepSeek的兴趣突然爆发,我们立刻行动起来”。
DeepSeek撕开了美国人看待中国AI的一层迷雾:过去那种“神秘又夸张”的印象逐渐被取代,人们开始不得不面对这个更令人胆寒的现实。在这家初创企业崛起之前,许多美国公司和政策制定者仍相信,中国在人工智能领域远远落后于硅谷,他们还有时间做准备,要么追求与中国平起平坐,要么阻止它达到这个水平。
但现实是,DeepSeek所在的杭州以及中国其它高科技中心,正涌现出大量“小AI龙”,这是对AI初创企业的昵称。本土创业公司如MiniMax和Moonshot AI打造的聊天机器人在国内外迅速走红。阿里巴巴集团的通义千问系列大语言模型在多个权威排行榜上与谷歌、Anthropic的产品并驾齐驱;百度首席执行官李彦宏在4月还表示,百度的新超级计算机采用自研芯片组装,能造出与DeepSeek一样好的模型,甚至成本更低。
华为技术有限公司也因其设计的AI设备受到赞誉,这些产品正与英伟达(Nvidia)所制造的高端GPU展开竞争,而英伟达GPU正是目前美国和欧洲先进AI模型的计算核心。
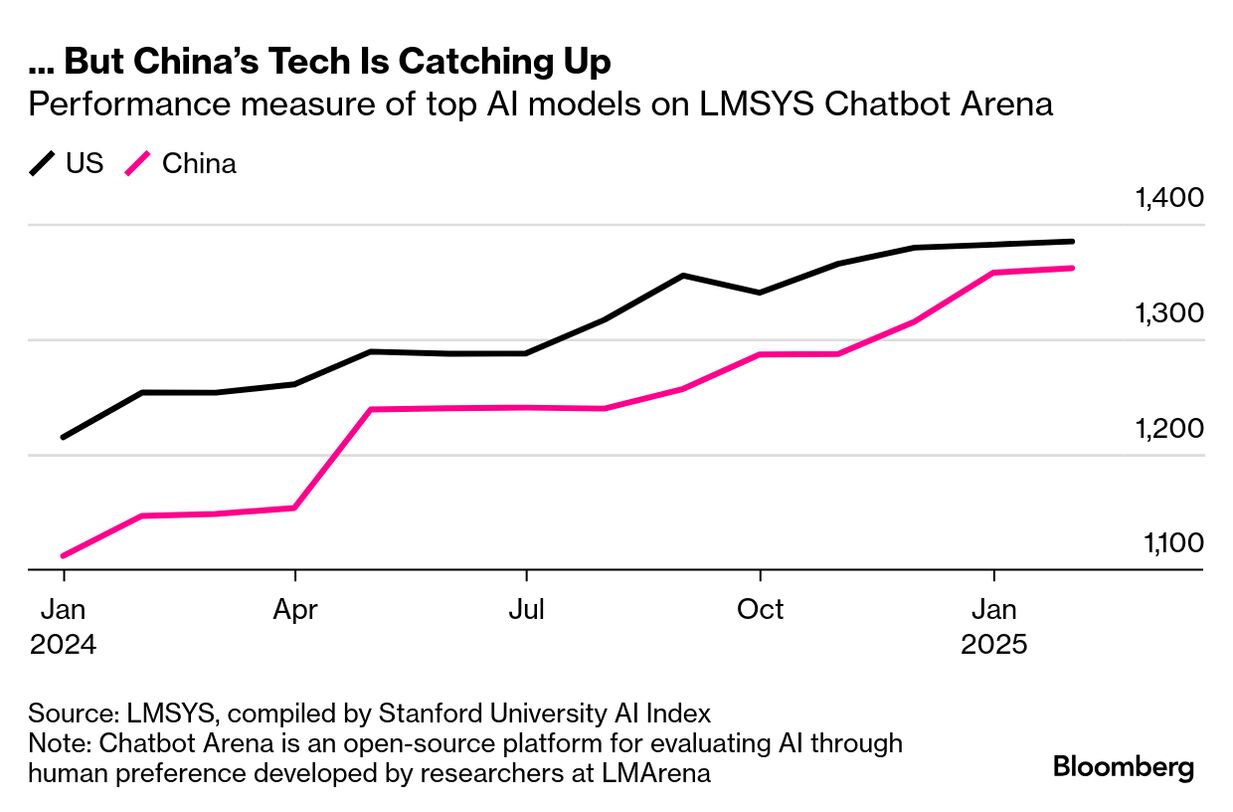
…但中国科技正在迎头赶上
几年前,中国共产党还在“给科技行业降温”,认为这个行业发展过快、管控不足。当局发起了反垄断调查和数据合规审查,像阿里巴巴联合创始人马云这样的科技明星也淡出了公众视野;社交媒体、零工经济平台和游戏应用也被强加了新规。而现在,面对外部干预,中共开始大力扶持本国科技产业。中国国家主席习近平正在集中资源发展人工智能和半导体产业,鼓励高技能人才,并呼吁建立一个“自主可控、协同高效”的软硬件生态系统。
那些原本用来限制中国AI发展的地缘政治限制,反而也推动了中国的技术进步。Counterpoint科技市场研究公司的分析师孙炜指出,中美之间在AI上的差距,如今已经不是以“年”而是以“月”来衡量了。他说:“中国有一种集体主义精神,以及一种愿意拼命干活的劲头,这让执行力更强。”
他还提到,由于英伟达芯片的短缺,中国反而激发出一些新颖的AI创新。
他说:“这种局面就像达尔文式的生存压力,谁能用更少资源做出更多,谁就能活下来。”
在中国眼里这是“创新”,但许多美国人仍然怀疑这背后存在不正当行为。美国国会众议院的一个两党委员会在四月发布报告,称DeepSeek与中国政府之间存在“重大”关联,指控该公司非法窃取了OpenAI的数据,构成了对美国国家安全的“深层威胁”。Anthropic公司首席执行官阿莫代伊(Dario Amodei)也呼吁加强美国出口管制,他在一篇3400字的博文中表示,DeepSeek肯定偷偷进口了大量英伟达GPU,包括其最先进的H100芯片。(彭博社近日也报道称,美国官员正在调查DeepSeek是否通过新加坡的第三方购买禁运芯片,从而绕过出口限制。)
中国驻美大使馆回应说,众议院委员会的指控“毫无根据”。英伟达也表示,DeepSeek使用的芯片符合出口规定,并称若对DeepSeek施加更多限制,反而会让中国的半导体产业受益。该芯片巨头的一位发言人表示,若迫使DeepSeek更多依赖国产芯片和服务,反而会“扶持华为以及其它海外AI基础设施供应商”。
而身处争议中心的DeepSeek,依然神秘莫测。该公司以开源AI技术为荣,但对自身的运作方式和意图却讳莫如深。它会在公开论文中披露极其具体的研究细节,却不愿透露基本的信息,比如其AI建模的成本、当前使用的GPU配置,或者数据的来源。
“我们不知道DeepSeek真正的动机,它就像一个黑箱。”
梁文锋本人的性格也让人难以接近,中国AI圈的一些领导人私下称他为“技术狂人”,这是专属那些性格古怪、野心极大的创业者的绰号。他过去10个月从未接受媒体采访,直到最近一次与中国国务院总理李强同场出席听证会时,他那张戴着眼镜、略显稚气的脸才首次被拍到。梁和他的同事们没有回应记者多次的采访请求,只有一名员工的自动回复写道,该邮件“正在处理”,“感谢您对DeepSeek的关注与支持!”
为了进一步了解这家公司如何运作,以及它在中国AI战略中的地位,《彭博商业周刊》采访了11位DeepSeek前员工,以及30多位了解中国AI行业的分析师、风险投资人和企业高管。
DeepSeek创始团队曾靠炒股程序起家,如今其AI技术被美国公司“用着怕着”
由于始终没有公开露面,像阿莫代伊(Dario Amodei)和OpenAI掌门人奥特曼这样的批评者得以填补这一“空白”,不断散布质疑,这些言论在美国听众中尤其有市场,他们早已习惯将中国科技视为神秘莫测的威胁。
不过,即使是那些对DeepSeek心存警惕的人,如今也不得不正视其AI的强大实力。
Perplexity AI公司的首席商务官谢韦连科(Dmitry Shevelenko)说,他公司的任何员工都没能联系上DeepSeek的任何人。但即便如此,Perplexity仍然采用了DeepSeek的技术,仅在美国和欧洲的服务器上运行,并重新训练模型,去除任何与中共审查有关的数据集。
他们将这一版本命名为R1 1776(象征美国建国年份),谢韦连科表示这是一种“向自由致敬”。
他说:“我们不知道DeepSeek的真实动机是什么,它就像一个黑箱。”
DeepSeek早就预料到其AI技术可能在海外引发担忧。2024年3月,在英伟达开发者大会的一场被人忽视的线上演讲中,DeepSeek的深度学习研究员陈德立曾提到,语言大模型(LLMs)中的价值观应当被“解绑”,以便适应不同社会。在一张冷静而理性的演示幻灯片中,陈展示了一个DeepSeek原型,可以根据使用者的社会背景调整聊天机器人的伦理标准。只需点击一个按钮,开发者就可以设定赌博、安乐死、性工作、持枪、大麻和代孕等议题的合法性。“他们只需要选中符合自己需求的选项,就能获得量身定制、契合其价值观的模型服务,”陈解释说。
在DeepSeek,“寻找高效变通的方法”一直是文化常态。早在2000年代中期,梁文锋和他的朋友在浙江大学攻读各类技术专业,机器学习、信号处理、电子工程等。为了好玩(也为了赚钱),他们在全球金融危机期间开发出了股票交易程序。
毕业后,梁开始独自开发量化交易系统,赚得一笔小财富。随后,他和几位大学好友在杭州合作创业,2015年成立了后来被称为“九坤量化”(High-Flyer Quant)的公司。
早期的招聘广告非常吸睛,宣称吸引了来自Google和Facebook的顶尖人才,寻找的是具备“怪才魅力”的数学和编程极客,就像情景喜剧《生活大爆炸》里的谢尔顿。他们承诺提供免费零食、Herman Miller的人体工学椅、德州扑克之夜、T恤加拖鞋的宽松文化氛围,还有一丝“金融科技兄弟文化”的调调,比如可以和“温柔可人的90后女生”和“从华尔街回来的冷艳女神”共事。
正如之后的DeepSeek一样,九坤也刻意营造出神秘气质,公司首条社交媒体发文只提到梁的代号“L先生”,同时又在某些方面追求透明。例如每周五,九坤都会在微信上发布旗下10只原创基金的表现图表。直到2016年夏天开始将这些数据限制为仅限注册投资者可见之前,这些基金组合的年化收益平均达到35%。
最终,九坤吸引了数十亿美元的资金,其投资和研究团队扩充到超过100人。2019年,梁开始全力组建AI部门,希望通过挖掘海量数据来发现被低估的股票、捕捉高频交易中的细微价格波动,甚至挖掘那些行业投资者忽视的宏观趋势。到新冠疫情初期,他和团队已经构建出一个由多颗处理器协同运行的高性能计算系统(即计算集群)。据九坤介绍,他们为这一集群配备了1000块英伟达2080Ti芯片(通常用于游戏和3D设计)以及100块Volta系列GPU(即V100,英伟达首款专为AI优化的芯片)。在旧系统下,训练一个新的经济模型需要两个月;但在新系统加持下,训练时间缩短到不到四天。
DeepSeek从量化交易起步,押注大规模AI计算转型,瞄准通用人工智能
这些用于金融的AI模型虽然表现亮眼,但规模仍远不及OpenAI等美国公司开发的通用模型。梁文锋推动建造一套更大规模的超级计算集群,采用英伟达最新的A100 GPU,这款芯片是V100的升级版。曾参与该项目的一位前九坤工程师表示,梁是这个集群中“使用量最大的人”,估计有80%的计算资源都分配到他的用户名下。这位工程师说,梁对深度学习几乎到了痴迷的程度,称其为“他烧钱的爱好”。虽然投下数亿美元打造AI基础设施对一家量化交易公司而言似乎有些“过头”,但梁早已赚得盆满钵满,完全负担得起。“对当时的梁来说,这是小钱,”该工程师回忆道。“算力越多,模型越好,交易利润也就越大。”
至少他们当时是这么想的。2021年12月,管理着约141亿美元资产的九坤量化致信投资人,为一段时间以来令人失望的投资回报表示歉意。公司将回撤归咎于AI系统,称其虽然选股精准,但在疫情带来的剧烈波动中,未能精准把握卖出时机。即便如此,九坤仍决定“加倍下注”AI。2022年1月,九坤在社交媒体宣布,已采购了5000块英伟达A100,每块价格通常高达数万美元。同年3月,又宣布计算集群已扩展至1万块,仅仅六个月后,英伟达就警告美国的新出口限制可能会影响这类芯片对中国的出口。
这些基础设施到底有多少是用于量化交易,又有多少是梁的“烧钱兴趣”,仍不清楚。2023年春,距OpenAI推出ChatGPT约五个月后,梁将DeepSeek拆分为一家独立的研究实验室。在杭州和北京的两个办公室里,金融已不再是焦点。在一份未署名的宣言中,九坤高调宣布将摒弃平庸,直面AI革命中最难的挑战,终极目标是:通用人工智能(AGI)。
2023年全年,DeepSeek实验室全速推进多项项目,包括AI编程助手、通用知识聊天机器人,以及文字转3D图像生成器。梁从九坤调来工程师,又从微软北京办事处、中国顶尖科技公司和大学招募新人。2023年9月,尚未开始读博的学生刘博(英文名Benjamin)以实习研究员身份加入。他说梁常将关键任务交给实习生,这些任务在别的公司通常是高级工程师才能接触的。“拿我来说吧:当我加入公司时,还没有人负责RLHF的基础架构(即‘人类反馈强化学习’所需的系统),所以他就让我来做。他会信任你去做那些从没人做过的事。”(这种信任对公司也有实质好处:DeepSeek给实习生的日薪是140美元,外加420美元的住房补贴,虽然在中国算是高薪,但仅为美国AI公司的实习工资三分之一,更远低于硅谷全职工程师的收入。)
据两位DeepSeek前研究员透露,梁早早押注“稀疏模型”(sparsity)这一新技术,它能通过“分工”方式更高效地训练和运行大语言模型(LLM)。在最早的ChatGPT中,无论是回答“2+2是多少”还是提供派的食谱,整套模型都会被激活;而稀疏模型则按功能划分为多个“专家”,每次只激活相关部分,从而更合理地利用资源。
DeepSeek发布V3模型震撼全球AI圈,训练成本低到令人难以置信
稀疏模型(sparse model)策略虽然能大幅降低算力成本,但复杂性极高。如果一个问题没有被正确分派到足够多的“脑回路”,或被送错“脑区”,模型的回答质量就会下降。(比如,“数学脑”知道怎么在公式中用π,但可能不知道派里面要放什么食材。)谷歌和法国独角兽Mistral在这方面已有突破,Mistral于2023年12月发布的稀疏模型由8个“专家”组成,每次提问只会激活其中两个最相关的部分。
梁文锋受到启发,鼓励团队打造拥有更多“专家”的模型,这虽然可能提升性能,但也会增加“幻觉”(模型产生错误信息)的风险,并可能导致知识碎片化。一位前DeepSeek员工透露:“这在公司内部引发了不少争论。”
但DeepSeek的进展接踵而至,每一次都公开发布,也越来越引起中国竞争者的关注。2024年末,DeepSeek发布了V3通用型AI模型,其规模比当时开源领域最大的大模型,Meta公司的同类产品大了约65%。不过,更令谷歌、OpenAI和微软高管震惊的,是DeepSeek发布的一篇长达数十页的V3研究论文,就在R1模型走红前一个月。论文中一个引爆点数据引人注目:
DeepSeek暗示V3的整体开发成本仅为560万美元。
很可能这个数字仅指最后一轮模型训练的精炼过程,但许多人误认为这是整个项目的总成本,这在行业中简直是“白菜价”。
相比之下,目前最先进的大模型通常需要1亿美元以上的训练成本。
Anthropic的阿莫代伊曾预测(在DeepSeek崛起前)下一代模型训练成本将高达一百亿甚至一千亿美元。
Hugging Face公司的研究负责人冯·韦拉(Leandro von Werra)指出,DeepSeek模型中最令人印象深刻的并非其“架构创新”,而是它显然拥有高质量的训练数据。这些数据要么是巧妙清洗过的互联网内容,要么通过其它手段提取。他说:“没有强大的数据集,模型就不会有好表现。从报告中可以明显看出,DeepSeek拥有目前最优秀的大模型训练数据集之一。但遗憾的是,这份50页的报告只用了半页讲数据。”
DeepSeek之所以进展迅速,是因为梁文锋将“开源精神”视为其核心理念。
他认为,像OpenAI和谷歌那样隐藏核心技术、对强大模型收费,只是追求短期利益,而非真正的长期成功。
相反,将模型完全公开且大多免费,是推广技术、让创业者和研究人员基于其平台开发应用的最高效方式。这样能形成“产品使用—反馈—优化”的飞轮效应。
大约两年前,DeepSeek在首次发布其开源大模型时就引用了Linux系统创始人的一句话:“嘴上说没用,给我看代码。”
“他们根本不缺钱。随着‘六小龙’爆红,市场上大量资金正砸向他们。”
2025年4月的一个阴天,在杭州萧山国际机场,到达旅客被阿里巴巴、字节跳动和华为等公司投放的AI广告牌包围。一位蓝发人形机器人在现代化航站楼内挥手迎宾;而在外面,一家初创企业正在测试小型自动驾驶货运卡车,用于停机坪的货物转运。尽管DeepSeek热度很高,但西方世界似乎忘了,这家公司只是中国数十个“硅谷”中崛起的众多AI“小龙”之一。
在杭州这座拥有1250万人口的超级城市,DeepSeek是“六小龙”这一科技新贵团体中的佼佼者。
|
|
 长登之痛 (2006-1-16) daomeidan1234
长登之痛 (2006-1-16) daomeidan1234  所谓爱情的那些破事儿 (2014-12-31) rebecca83
所谓爱情的那些破事儿 (2014-12-31) rebecca83 

 发表于 2025-5-15 08:08
发表于 2025-5-15 08:08




 发表于 2025-5-15 08:23
发表于 2025-5-15 08:23